-
SQLD 02_03 SQL 최적화 기본 원리 요약공부 !/Data 2022. 3. 4. 13:36반응형
OPTIMIZER
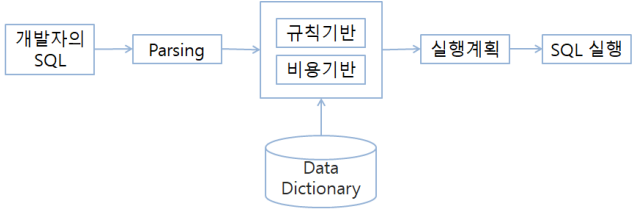
SQL 개발자가 SQL를 작성하여 실행할 때, 옵티마이저는 SQL를 어떻게 실행할 것인지 계획한다
옵티마이저는 SQL 실행계획 ( Execution Plan ) 를 수립하고 SQL를 실행하는 DBMS 의 SW 이다
SQL 성능에 아주 중요한 역할 !
옵티마이저 특징
데이터 딕셔너리에 있는 오브젝트 통계, 시스템 통계 등 정보를 사용해서 예상되는 비용을 산정한다
최저 비용을 가진 계획을 선택하여 SQL를 실행한다
옵티마이저 종류
옵티마이저 실행방법은 개발자가 SQL를 실행하면 Parsing 실행하여 SQL 구문 검사 및 구문 분석을 실행한다
분석이 완료되면 옵티마이저가 규칙 기반 혹인 비용 기반으로 실행 계획을 수립한다
기본적으로 통계 정보를 활용하는 비용 기반의 옵티마이저를 사용한다
실행 계획 수립이 완료되면 최종적으로 SQL를 실행하고 데이터를 인출( Fetch ) 한다
옵티마이저 엔진
옵티마이저 설명 Query Transformer SQL문을 효율적으로 실행하기 위해 옵티마이저가 변환한다
SQL문이 변환되어도 결과는 동일하다Estimator 통계정보를 사용하여 SQL 실행 비용을 계산한다
총 비용은 최적의 실행 계획을 수립하기 위함이다Plan Generator SQL를 실행할 실행 계획을 수립한다 규칙 기반 옵티마이저
15개의 우선순위를 기준으로 실행 계획을 수립한다
최신 Oracle 기본적으로 비용 기반 옵티마이저를 사용한다

비용 기반 옵티마이저
예상되는 소요시간이나 자원의 사용량인 총비용을 오브젝트 통계나 시스템 통계를 사용하여 계산한다
총 비용이 적은 쪽으로 실행 계획을 수립하고 통계정보가 부적절한 경우 성능 저하가 발생할 수 있다
INDEX
데이터를 빠르게 검색할 수 있는 방법을 제공한다
인덱스는 키로 정렬되어 원하는 데이터를 빠르게 조회할 수 있다
오름차순 (ASE), 내림차순(DESC) 탐색이 가능하다
한 테이블에서 여러 개를 생성할 수 있고 여러 개의 칼럼으로 구성될 수 있다
테이블을 생성할 때 자동으로 PK 생성된다 ( SYSXXXX )
인덱스는 Root Block, Branch Block, Leaf Block 로 구성된다
Root Block : 트리에서 가장 상위 노드
Branch Block : 다음 단계의 주소를 가진 포인터로 구성
Leaf Block : 키와 RowId 로 구성되어 있고 Double linked list 로 구성되어 양방향 탐색 가능
생성
CREATE INDEX 인덱스명 테이블명 ON 테이블명 ( 칼럼명1 차순, 칼럼명2 차순 ... )
한 개 이상의 칼럼을 사용하여 생성할 수 있다
CERATE INDEX IND EMP ON EMP ( ENAME ASC, SAL DESC );스캔
Index Unique Scan
유일스캔은 키 값이 중복되지 않는 경우에 사용된다
SELECT * FROM EMP WHERE EMPNO = 100Index Range Scan
Leaf Block의 특정 범위를 스캔한 것으로 SELECT 문에서 특정범위를 조회하는 WHERE 문을 사용할 경우
Like, Between이 대표적인 예시, 데이터의 양이 적은 경우 자체를 실행하지 않고 TABLE FULL SCAN 됨
SELECT EMPNO FROM EMP WHERE EMPNO >= 100;Index Full Scan
검색되는 키가 많은 경우에 Leaf Block의 처음부터 끝까지 전체를 읽는다
SELCET ENAME, SAL FORM EMP WHERE ENAME Like '%' AND SAL > 0;
OPTIMIZER JOIN
Nested Loop Join
한 테이블에서 데이터를 먼저 찾고 다음 테이블을 조인하는 방식이다
먼저 조회되는 테이블을 외부 테이블 Outer Table
다음에 조회되는 테이블을 내부 테이블 Inner Table 라고 한다
데이터 스캔 범위를 줄이기 위해 외부 테이블의 크기가 작은 것을 먼저 찾는 것이 중요하다
Nested Loop 조인은 Random Access 가 발생하는데 많이 발생하며 성능지연이 발생한다
이러한 특성 때문에 데이터 양이 적을 때 사용한다
Nest Loop 조인의 절차는
1) 선행 테이블에서 조건을 만족하는 첫번째 행을 찾는다
2) 선행 테이블의 조인 키를 갖고 후행 테이블의 조인 키가 존재하는지 찾아 조인을 시도한다
3) 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인한다
4) 인덱스에서 추출한 레코드 식별자를 이용해 후행 테이블에 엑세스한다
SELECT /*+ ordered use_nl(b) */ * FROM EMP a, DPT b WHERE a.NO = B.NO AND a.NO = 10;Sort Merge Join
두 개의 테이블을 Sort_Area 라는 메모리 공간에 모두 로딩하고 정렬하여 병합한다
정렬이 발생하므로 데이터의 양이 많으면 성능이 떨어진다
임시 영역은 디스크에 있기 때문에 성능이 급격히 떨어진다
PK 와 FK 관계에서 FK 인덱스가 없을때 Sort Merge 방식으로 옵티마이저가 동작한다
SELECT /* ordered use_merge(b) */ * FROM EMP a, DPT b WHERE a.NO = b.NO AND a.NO = 10;Hash Join
두 개의 테이블 중에서 작은 테이블을 hash 메모리에 로딩하고 조인 키를 사용하여 해시 테이블을 생성한다
Equal Join 만 사용이 가능하고 해시 함수를 사용해서 주소를 계산하고
해당 주소를 사용해서 조인하므로 CPU 연산을 많이한다
Hash 조인 시에는 선행 테이블이 충분히 메모리 로딩되는 크기여야한다
SELECT /*+ ordered use_hash(b) */ * FROM EMP a, DPT b WHERE a.NO = b.NO AND a.NO = 10;
참고
데이터 전문가 포럼 (빅데이터분석기사... : 네이버 카페
빅데이터분석기사, ADP, ADsP, SQLP, SQLD, DAP, DAsP, 자격증 취득 등 데이터 전문가 커뮤니티입니다.
cafe.naver.com
반응형'공부 ! > Data' 카테고리의 다른 글
Vector DataBase, 너 누군데 .. (0) 2025.01.21 SQLD 01_01 데이터 모델링의 이해 요약 (0) 2022.03.07 SQLD 01_02 데이터 모델과 성능 요약 (0) 2022.03.07 SQLD 02_01 SQL 기본 요약 (0) 2022.03.06 SQLD 02_02 SQL 활용 요약 (0) 2022.03.02