-
SQLD 01_02 데이터 모델과 성능 요약공부 !/Data 2022. 3. 7. 01:27반응형
정규화
최소한의 데이터 중복, 최대한의 데이터 유연성, 데이터 일관성을 위해 데이터를 분리하는 과정이다
정규화를 통해 데이터 모델의 독립성을 확보하고 데이터 모델의 변경을 최소화할 수 있다
정규화절차
정규화 절차 설명 함수적 종속성 제1정규화 속성의 원자성을 확보하며 PK 설정 완전 함수 종속성 제2정규화 PK가 2개 이상의 속성으로 이루어진 경우,
부분 함수 종속성 제거부분 함수 종속성 제3정규화 PK를 제외한 칼럼 간 종속성 제거 = 이행 함수 종속성 제거 이행 함수 종속성 BCNF PK를 제외하고 후보키가 있는 경우,
후보키가 기본키를 종속시키면 분해한다정규화와 함수적 종속성
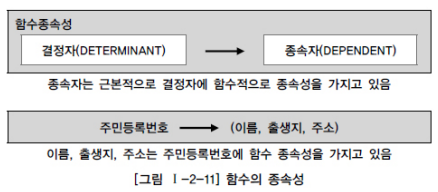
정규화는 함수적 종속성을 근거로 한다
함수적 종속성은 데이터들이 어떤 기준값에 의해 종속되는 현상으로 기준값을 결정자 종속되는 값을 종속자라 한다
제1정규화
딱 하나의 유일한 값 기본키를 잡는 것이 제1정규화이다
종속자가 PK에만 종속되는것이 완전 함수 종속성이다
릴레이션에 속한 모든 속성의 도메인이 원자값으로만 구성되어 있으면 제1정규형에 속한다
제2정규화
부분 함수 종속성을 제거하는 것이다
PK가 2개 이상의 칼럼으로 이루어진 경우에 발생한다

제3정규화
이행 함수 종속성을 제거하는 것이다
PK를 제거한 칼럼 간 종속성이 발생하는 것으로 제1정규화와 제2정규화를 거친 뒤 수행해야한다
ex) x → y , y → z 라는 종속 관계일 경우 x → z 가 성립될 때

반정규화
정규화는 데이터의 중복을 제거하여 데이터 모델의 유연성을 높이고 성능향상에 도움을 준다
하지만 데이터 조회시 CPU, 메모리 사용량이 크다
이런 부분을 해결하기 위해 반정규화를 적용한다
DB 성능 향상을 위해 데이터 중복을 허용하고 조인을 줄이는 방법이다
조회 속도는 향상되지만 데이터 모델의 유연성은 낮아진다
반정규화를 수행하는 경우
- 정규화에 충실하면 종속성, 활용성은 향상되지만 수행 속도가 늦어지는 경우
- 다량의 범위를 자주 처리해야 하는 경우
- 특정 범위의 데이터만 자주 처리하는 경우
- 요약/ 집계 정보가 자주 요구되는 경우
- 반졍규화 정보에 대한 재현의 적시성으로 판단 ( 여러 테이블에 대해 다량의 조인이 필요한 경우 )
반정규화 절차
1) 반정규화 대상 조사
범위처리빈도수 조사, 대량의범위처리 조사, 통계성프로세스 조사, 테이블조인 개수 조사
2) 다른 방법으로 유도 조사
반정규화 외 다른 방법이 있는지 조사
- 클러스터링 : 인덱스 정보를 저장할때 물리적으로 정렬해 저장하는 방법,
인접 블록을 연속적으로 읽기 때문에 성능이 향상된다 - 파티셔닝 : 논리적으로 한 테이블이지만 여러 데이터 파일에 분산되어 저장하는 것
데이터 조회시 엑세스 범위가 줄고 데이터가 분할되어 I/O 성능이 향상된다
파티션을 독립적으로 백업/ 복구할 수 있다- Range 파티셔닝 : 데이터값의 범위를 기준
- List 파티셔닝 : 특정 값을 지정
- Hash 파티셔닝 : 해시함수를 적용
- Compoiste 파티셔닝 : 범위와 해시를 복합적으로 사용
3) 반정규화 수행
반정규화기법 : 테이블 반정규화
테이블병합
기법 내용 1:1 관계 테이블 병합 1:1 관계를 통합하여 성능 향상 1:M 관계 테이블 병합 1:M 관계를 통합하여 성능 향상 수퍼/ 서브 타입 테이블 병합 수퍼/ 서브( 부모-자식) 관계를 통합하여 성능 향상 수퍼/ 서브 타입 변환 방법 : 데이터 양 & 트랜잭션의 유형에 따라

테이블분할

테이블추가
기법 내용 중복테이블 추가 다른 업무거나 서버가 다른 경우
동일 테이블 구조를 중복하여 원격 조인을 제거하여 성능 향상통계테이블 추가 SUM AVG 등을 미리 수행하여 계산해둠으로 조회 시 성능 향상 이력테이블 추가 이력 테이블 중 마스터 테이블에 존재하는 레코드를 중복하여 성능 향상 부분테이블 추가 한 테이블의 전체 칼럼 중 자주 이용하는 집중화된 칼럼들의 I/O 를 줄이기 위해
해당 칼럼을 모아놓은 별도의 테이블 생성칼럼 반정규화
기법 내용 중복칼럼 추가 조인을 감소시키기 위해 칼럼 중복 파생칼럼 추가 계산에 의해 발생되는 성능 저하를 예방하기위해 미리 값을 계산한 칼럼 추가 이력테이블칼럼 추가 불특정 조회로 인한 성능 저하를 예방하기위해
이력 테이블에 기능성 칼럼 ( 최근값 여부, 시작과 종료일자 등 ) 추가PK에 의한 칼럼 추가 단일 PK 내에서 특정 값을 조회하는 경우 생기는 성능저하를 예방하기위해
이미 존재하는PK 데이터를 일반 속성으로 포함하는 칼럼 추가응용시스템 오작동을 위한 칼럼 추가 업무적으로는 의미가 없지만 사용자의 잘못된 데이터 처리로 원래 값 복구를 원하는 경우, 이전 데이터를 임시적으로 중복하여 보관하는 칼럼 추가 관계 반정규화
중복 관계 추가 : 데이터 처리를 위한 여러 조인이 발생시키는 성능 저하 예방을 위해 추가적으로 관계를 맺음
Row Chaining
새로운 데이터가 입력될 때 삭제되고 생긴 빈 공간에 입력되지만 그 빈 공간이 부족할 경우
새로운 블록에 나머지 데이터가 입력되는 것을 의미한다
로우 길이가 길어 데이터 블록 하나에 데이터가 모두 저장되지 못하고 두 개 이상으로 걸쳐진 모양이다
Row Migration
변경작업에 의해 공간이 더 필요한데 저장공간이 없을 경우 새로운 블록으로 이동시켜 변경작업을 수행하는 것
분산데이터베이스
DB를 연결하는 빠른 네트워크 환경을 이용해 DB를 여러 지역의 여러 노드로 위치시켜
사용성/ 성능 등을 극대화시킨 DB 이다 ( 특정 서버 부하 집중 → 부하 분산 )
분산데이터이스 투명성 ( Transparency )
투명성 설명 분할투명성 고객은 하나의 논리적 릴레이션이 여러 단편으로 분할되어 각 단편의 사본이 여러 시스템에
저장되어 있음을 인식할 필요가 없다위치투명성 고객이 사용하려는 데이터 저장장소를 명시할 필요가 없으며 고객은 데이터가 어디있든
동일한 방법으로 데이터 접근이 가능해야한다지역사상투명성 지역DBMS와 물적DB 사상이 보장되어 각 지역 시스템 이름과 무관한 이름을 사용할 수 있다 중복투명성 DB객체가 여러 시스템에 중복되어 존재해도 고객과는 무관하게 데이터 일관성이 유지된다 장애투명성 DB가 분산된 각 지역의 시스템이나 통신망에 이상이 생겨도 데이터 무결성은 보장된다 병행투명성 여러 고객의 응용프로그램이 동시에 분산DB에 대한 트랜잭션을 수행해도 결과에 이상이 없다 분산데이터베이스 장단점
장점 단점 신뢰성/ 가용성/ 효용성/ 융통성 높다 설계/ 관리가 복잡하고 비용이 높다 병렬처리 수행시 빠른 응답과 통신비용이 낮다 데이터 무결성에 대한 위협 존재한다 시스템 용량 확장이 쉽다 보안 관리/ 통제 어렵고 오류 잠재성이 크다 각 지역 사용자들의 요구 수용 빠르다 응답 속도 불규칙하다
참고
데이터 전문가 포럼 (빅데이터분석기사... : 네이버 카페
빅데이터분석기사, ADP, ADsP, SQLP, SQLD, DAP, DAsP, 자격증 취득 등 데이터 전문가 커뮤니티입니다.
cafe.naver.com
반응형'공부 ! > Data' 카테고리의 다른 글
Vector DataBase, 너 누군데 .. (0) 2025.01.21 SQLD 01_01 데이터 모델링의 이해 요약 (0) 2022.03.07 SQLD 02_01 SQL 기본 요약 (0) 2022.03.06 SQLD 02_03 SQL 최적화 기본 원리 요약 (0) 2022.03.04 SQLD 02_02 SQL 활용 요약 (0) 2022.03.02